Data Placement and Distributed Multimedia Indexes
This sub-project aims at developing high-performance multimedia information-system technology.
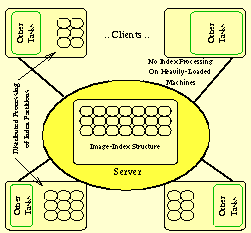
Our focus in this sub-project is on data placement and distributed processing of multimedia indexes. Image retrieval is based on one or a number of image characteristics:
Extracted Features:
Features extracted from images can be used to characterise colour and texture distributions within images. Such information is typically high-dimensional vectors. For colour features, in our case, these a vectors of 45 integers.
Pictorial Content:
Pictorial content refers to the objects contained in an image and their spatial relationships; for example: "A tree, above two people, to the left of a house''. Such information is typically represented through string encodings.
Metadata:
Metadata is data about images: Where captured? When? By whom? Using what method? How processed? Title? Description of contents? All this information can be used to support query processing.
n a related project (ImageInd), we are investigating strategies for indexing such data on combinations of such information. This has lead us to develop a signature-based access structure. In this project, we are addressing the problem of mapping such an access structure to storage devices and query processing in distributed environments.
Our approach is illustrated in the figure above. Index processing requires visiting large parts of the index structure. To optimise this processing, we exploit the CPU and primary- and secondary-memory resources of an array of networked work-stations. The advantage of this approach is that, for good signature functions and moderate data sets index processing can come close to a main-memory operation. For larger data sets, I/O activities can be parallelised.
A challenge is to exploit networked workstations without over-exploitation to the extent no resources remain to support for other tasks. This requires dynamic cache and processing relocation strategies which can be realised without coalescing on-going query-processing activities, including insertions. Implementation tasks within this project are being carried out within the prototype system. Our part in this project is funded by the BBW (93.0135), and the project as a whole is funded under the ESPRIT initiative (9141). Our activities are closely related to those in the project.
Patient Similarity Search:
In a related project with medical computer scientists from the Universite of Heidelberg (Prof. Haux, Dr. Winter and Dr. Glück), similarly distribution techniques are being used for the processing of signature-based index structures for similarity search over medical patient records.
Project Partners:
This sub-project is part of the ESPRIT project (9141) with partners in Greece (MUSIC/TUC), Germany (GMD-IPSI) and Italy (CNR-IEI) aims at developing high-performance multimedia information-system technology.
Funding: